
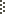

Авторы доклада: Кирилл Николаев («Яндекс», kvn@yandex-team.ru), Екатерина Зудина («Яндекс», zudina@yandex-team.ru), Андрей Горшков («Яндекс», gorshkov@yandex-team.ru).
Это — перевод мадридского доклада «Яндекса» на русский язык. Оригинал доклада на английском лежит здесь (pdf).
Аннотация
Для искусственного повышения позиции коммерческих сайтов в результатах поиска, оптимизаторы платят за получение внешних ссылок на продвигаемые ресурсы. Возможность идентифицировать платные ссылки позволяет улучшить качество поиска. В этой работе, мы представляем новый метод обнаружения подобных ссылок.
Он заключается в создании тематического классификатора текстов ссылок и анализе разнообразия тем исходящих коммерческих ссылок на документе. Эти данные затем используются в анализе ссылочного графа Рунета для определения документов, продающих ссылки, сайтов, их покупающих, и, в конечном итоге, для идентификации платных ссылок.
Проверка алгоритма на размеченных вручную выборках ссылок показала высокую эффективность данного метода.
Категории и тематики:
Н.3.3 [Поиск и извлечение информации]: Фильтрация данных.
Основные понятия:
Алгоритмы, разработка, эксперимент.
Ключевые слова:
Поисковые машины, языковая модель, категоризация, анализ ссылок, машинное обучение, извлечение данных из Сети.
§1. Введение
На сегодняшний день, основным методом поисковой оптимизации в Рунете являются платные ссылки. Платные ссылки оказывают искусственное воздействие на результаты поиска, но мы отделяем их от обычных спам-ссылок, так как платные ссылки часто встречаются на авторитетных страницах, соседствуют с естественными полезными ссылками на одном документе и указывают на полезные коммерческие сайты.
Часть таких ссылок имеет высокую стоимость, на их оформление тратят значительные усилия. Текст дорогой платной ссылки всегда содержит ключевые слова и выражения из семантического ядра сайта. Тысячи оптимизаторов занимаются подобной, часто ручной, разметкой продвигаемых ресурсов.
Таким образом, умение идентифицировать платные ссылки позволяет извлечь много полезной информации о размеченных ресурсах.
Наша работа состоит из двух частей. Первая часть — это определение типа и темы текста, вторая — формирование начального посева политематичных документов и разметка ссылочного графа с использованием модифицированного алгоритма HITS [1], в котором «посредникам» (hubs) соответствуют документы, продающие ссылки, а «авторам» (authorities) — сайты, покупающие ссылки. При этом, главная задача алгоритма — идентификация непосредственно платных ссылок, а не сайтов, их продающих или покупающих.
§2. Алгоритм
§2.1 Классификатор «SEO-text»
Параметр, который показывает, насколько текстовый фрагмент «коммерчески интересен», назовём показателем оптимизированности текста (SEO-text).
Первоначальный посев SEO-запросов был взят на популярном ресурсе оптимизаторов. На этой основе, был создан изначальный классификатор оптимизированности текста (аналогично [2], в котором использовались только 2 темы: «SEO» и «не-SEO»).
Затем, используя метод итераций, аналогичный описанному в 2.2, мы получили большой список слов (300 000) и двусловий (1 500 000), которые часто используются в текстах ссылок, ведущих на продвигаемые сайты. Для получения естественных словосочетаний, аналогичным образом был использован пул новостных текстов.
Таким образом, на основе этих данных, был сделан более эффективный байесовский текстовый классификатор.
§2.2 Классификатор «SEO-topic»
При создании алгоритма тематической категоризации, были использованы 22 темы, наиболее типичные для продвигаемых сайтов (например, недвижимость, финансы, грузоперевозки и др.) Алгоритм определения темы состоит из 2 частей.
На первой стадии, мы вручную отобрали 3350 монотематичных слов. Каждое такое слово обладает узко выраженным тематическим спектром.
Затем, используя тексты ссылок с ненулевым показателем «SEO-text», мы распространили тематические спектры на другие слова, в соответствии с вероятностью их встречаемости в текстах ссылок вместе со словами из начального набора. Таким способом мы получили 64 000 тематических спектров, которые были использованы для тематической категоризации (аналогично [2]).
На второй стадии, был использован упрощённый host-to-host ссылочный граф с 20 миллионами рёбер, содержащих ссылочные тексты с ненулевым показателем «SEO-text». Для каждого ребра, мы определяли две наиболее вероятные темы по описанному выше алгоритму.
Далее, на основе данных о входящих рёбрах, вычислялись тематические спектры для вершин-целей, поэтому большинство целей имели узкие тематические спектры. Для таких целей мы распространили их тему на все тексты входящих ссылок и на базе этих текстов собрали новый словарь, содержащий 200 000 слов и 800 000 двусловий. Большой объём данных позволил нам создать новый эффективный тематический классификатор, основанный на цепи Маркова 1-го порядка.
Словарь был немного скорректирован вручную (с учётом грубых ошибок).
Таким образом, построение большого словаря не потребовало больших человеческих усилий. Фактически, мы использовали работу, уже проделанную оптимизаторами.
§2.3 Классификаторы «SEO-out» и «SEO-in»
Для дальнейшего анализа, был применён алгоритм, сходный с BHITS [4].
Существует много примеров использования алгоритма HITS и его модификаций для обнаружения спам-ссылок ([5], [6]). В нашем случае — он работает для определения платных ссылок.
Мы использовали двудольный ссылочный граф (документы-источники слева и хосты-цели справа), из которого были удалены все известные спам-документы, ссылки со спам-каталогов и т. п. Мы улучшили стандартную подготовку ссылок для HITS-алгоритма и удалили все ссылки внутри одного владельца (под владельцем, мы понимаем домен второго уровня, если это не хостинг, или домен третьего уровня, если он расположен на бесплатном хостинге).
Таким образом был получен ссылочный граф, содержащий 300 миллионов рёбер, 50 миллионов документов-источников и 19 миллионов сайтов-целей. Применив тематический классификатор (2.2) для рёбер графа, мы получили 1 миллион узко тематичных целей.
В нашем алгоритме, мы ввели показатели «SEO-out» и «SEO-in» (в классическом алгоритме HITS — «посредники» (hubs) и «авторы» (authorities), соответственно). «SEO-out» показывает вероятность того, что документ продаёт ссылки. Показатель «SEO-in» показывает вероятность того, что сайт продвигается с помощью платных ссылок. Сайты с высоким показателем «SEO-in», чаще всего — коммерческие ресурсы, которые используют дорогое продвижение, чтобы подняться в поисковой выдаче.
Документ, ссылающийся на сайты разных тематик, весьма вероятно — продаёт ссылки. Множество таких политематичных документов, имеющих исходящие ссылки с высоким показателем «SEO-text» и определённые значения других параметров, было использовано в качестве первоначального посева документов (3 миллиона).
Показатели «SEO-out» и «SEO-in» высчитываются аналогично стандартному алгоритму HITS за две итерации. На этой стадии, нашей целью было получить набор целей с высоким показателем «SEO-in». В итоге, было получено около 500 000 таких целей.

Рис. 1. Вычисление показателя «SEO-in» на основе значений «SEO-out» первоначального посева политематичных документов на двудольном ссылочном графе посредством HITS-алгоритма. Показана первая итерация, T1, T2, T3 — темы сайтов-целей.
§2.4 Классификатор «SEO-link»
Мы определяем показатель «SEO-link» как вероятность ссылки быть платной. Этот показатель высчитывается для каждой ссылки с помощью простого алгоритма за один проход по базе.
Сначала мы оцениваем вероятность того, что документ содержит платные ссылки («SEO-out» данного документа), агрегируя следующие параметры: среднее значение «SEO-in» целей ссылок с данного документа (AvgSEOin), среднее значение «SEO-text» текстов этих ссылок (AvgSEOtext), количество уникальных тем целей (NTh) и некоторые другие параметры документа по следующей формуле:
SEOout = k1*AvgSEOin + k2*AvgSEOtext + k3*NTh + … (1)
Затем, используя «SEO-text» текста ссылки, «SEO-out» документа-источника, «SEO-in» цели и некоторые другие параметры, мы вычисляем конечное значение «SEO-link» по следующей формуле:
SEOlink = l1*SEOtext + l2*SEOin + l3*SEOout + … (2)
Параметры «ki» и «li» были подобраны на основе обучающей выборки, состоящей из 2500 случайных ссылок, размеченных вручную, и около 10 000 ссылок, взятых, частично, из «Википедии», частично — из известных документов, продающих ссылки.
Вычисления, на данном этапе, не требуют большого объёма памяти и ресурсов процессора и могут производиться во время обработки ссылочной базы.
§3. Результаты
Для оценки точности и полноты наших алгоритмов, были использованы различные тестовые выборки, для разметки которых были привлечены восемь экспертов.
Для оценки алгоритма тематической классификации, были взяты (с популярного ресурса оптимизаторов) «верхние» 100 сайтов для каждой из 22 тематик. Случайным образом, было отобрано подмножество текстов входящих ссылок с ненулевым значением «SEO-text». Затем, если человек мог однозначно отнести текст ссылки к одной из 22 тем, то тема присваивалась данному тексту.
Большая часть получившейся выборки (12 100 текстов ссылок) была использована для настройки алгоритмов. Другая часть (3 800 текстов) — использовалась для оценки. В результате, точность и полнота тематического классификатора составили 94% и 97% соответственно.
Для оценки алгоритма идентификации платных ссылок, мы использовали 2 выборки (таблица 1).
Первая выборка содержит около 1700 полезных естественных ссылок, 1850 платных ссылок, выбранных из множества случайно взятых из индекса, и размеченных вручную ссылок (точность оценивалась только на этой естественной выборке). Также существует возможность напрямую идентифицировать часть ссылок с одной из ссылочных бирж. Используя этот факт, мы составили вторую выборку из заведомо платных ссылок.
Всего из 300 миллионов ссылок, присутствующих в графе, 50 миллионов были определены нашим алгоритмом как платные (17%).
Таблица 1. Результаты идентификации платных ссылок
|
Выборка |
Точность |
Полнота |
|
1. 3 550 ссылок |
95% |
93% |
|
2. около 140 000 ссылок |
— |
96% |
§4. Заключение
С помощью классификатора платных ссылок, можно по разному рассчитывать факторы ссылочной релевантности для коммерческих и некоммерческих запросов. Например, учитывать и использовать для улучшения коммерческого ранжирования платные ссылки или не учитывать. Использование классификатора в формуле ранжирования позволит улучшить качество поиска, уменьшить влияние чрезмерной оптимизации на некоммерческие запросы и повысить разнообразие поисковой выдачи.
Этот алгоритм может быть улучшен за счёт использования сегментатора документов в алгоритме microHITS для блоков ссылок [7].
§5. Благодарности
Мы благодарим Сергея Певцова, Илью Сегаловича, Аркадия Борковского и Сергея Волкова за полезные замечания.
Литература:
[1] Kleinberg, J. (1997). Authoritative sources in a hyperlinked environment. Journal of the ACM 46 (5): 604–632.
[2] T. H. Haveliwala. Topic-sensitive pagerank. In Proc. 11th International WWW Conference, pages 517-526, 2002.
[3] Lafferty J., Zhai, C. Document language models, query models, and risk minimization for IR. In Proceedings of SIGIR-2001, pp 111-119.
[4] K. Bharat and M.R. Henzinger, Improved algorithms for topic distillation in a hyperlinked environment, Proc. 21st Annual International ACM SIGIR, pp.104–111, 1998.
[5] B. Wu and B. Davison. Undue influence: Eliminating the impact of link plagiarism on web search rankings. Technical report, LeHigh University, 2005.
[6] Yasuhito Asano, Yu Tezuka, Takao Nishizeki. Improvement of HITS algorithms for spam links. APWeb/WAIM 2007, LNCS 4505, pp 479-490, 2007.
[7] S. Chakrabarti. Integrating the Document Object Model with Hyperlinks for Enhanced Topic Distillation and Information Extraction. ACM 1-58113-348-0/01/0005, 2001.
Ещё по теме:
- Долой «портянки»! Ещё раз о фильтре «Яндекса» на спамность текста
- Краткость — сестра таланта, или Фильтр «Яндекса» от 20 января
- 21 сайт, где можно добавить статью бесплатно
- Поисковые операторы «Google»
- СДЛ и «говносайт»: 5 основных отличий